Apa itu Clustering?
Clustering adalah teknik untuk mengelompokkan data berdasarkan kesamaan maupun perbedaan yang ada di antara data tersebut.
Tujuan adanya clustering yaitu untuk membagi set data menjadi kelompok-kelompok (kluster), di mana data dalam satu kelompok memiliki karakteristik yang mirip dan sekaligus berbeda dengan data di kelompok lain.
Clustering tidak memerlukan data pelatihan (training data) untuk mengelompokkan atau mengklasifikasikan objek data. Itulah sebabnya teknik ini termasuk dalam unsupervised machine learning. Sebaliknya, clustering mengidentifikasi pola intrinsik dalam data dan mengelompokkannya berdasarkan kesamaan tertentu.
Sebagai contoh, terdapat set data terdiri dari kumpulan buah berupa apel, pisang, dan jeruk. Teknik clustering akan mengelompokkan buah-buahan tersebut berdasarkan jenisnya, sehingga semua apel berada dalam satu kluster, semua pisang dalam kluster lain, dan seterusnya.
Manfaat Clustering
Ada berbagai manfaat clustering bagi bisnis, termasuk:
Memahami data secara mendalam
Dengan membagi data menjadi kelompok-kelompok terpisah, analyst dapat lebih mudah melihat pola, tren, dan hubungan antar data. Pengelompokan ini memungkinkan mereka memahami data perusahaan secara mendalam sehingga analisis yang dilakukan juga lebih detail.
Membuat segmentasi
Clustering adalah alat yang tepat untuk membuat segmentasi. Misalnya, dalam analisis customer, clustering dapat digunakan untuk mengidentifikasi kelompok pelanggan yang memiliki perilaku atau preferensi mirip.
Adanya segmentasi membantu perencanaan strategi pemasaran yang lebih efektif.
Mendeteksi anomali
Teknik clustering juga dapat digunakan untuk mendeteksi anomali, yaitu mengidentifikasi titik data yang tidak sesuai dengan pola data pada umumnya. Menemukan data yang aneh atau menyimpang sangat berguna dalam berbagai hal, seperti mendeteksi penipuan dan pemantauan jaringan.
Reduksi dimensi
Manfaat lain dari clustering yaitu bisa dimanfaatkan sebagai teknik reduksi dimensi. Dengan mengelompokkan variabel serupa, analyst dapat mengurangi jumlah variabel saat melakukan analisis tanpa kehilangan terlalu banyak informasi.
Metode Clustering
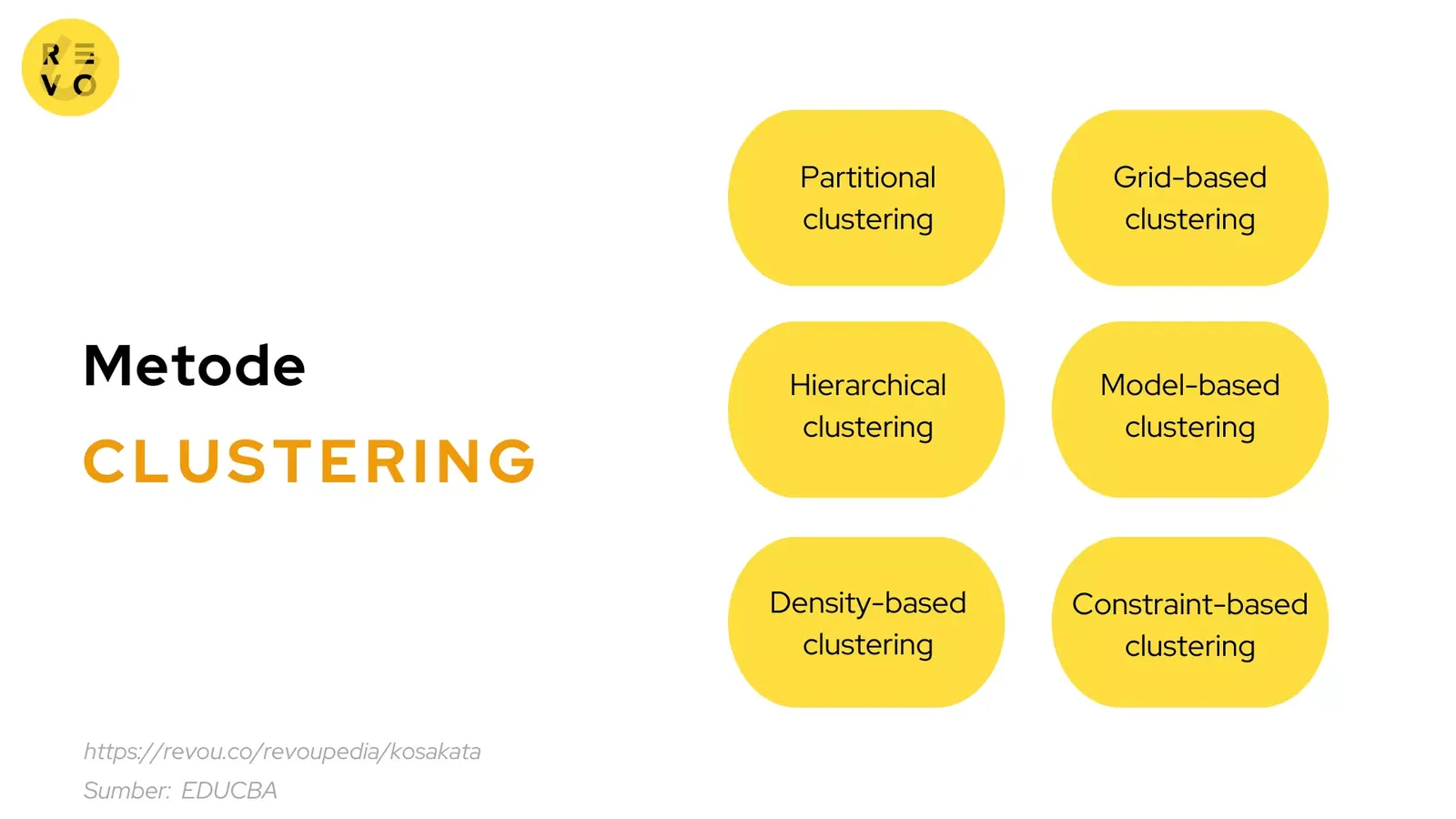
Dirangkum dari EDUCBA, berikut beberapa metode clustering:
#1 Partitional clustering
Metode partitional clustering adalah metode yang membagi data menjadi sejumlah non-overlapping subset atau cluster tanpa struktur hierarki tertentu. Metode ini mencakup teknik-teknik seperti K-Means, K-Medoids, dan CLARA.
Contohnya, K-Means bekerja dengan mengelompokkan data menjadi 'K' cluster berdasarkan jarak terdekat antara titik data dan titik pusat (centroid).
#2 Hierarchical clustering
Hierarchical clustering adalah metode yang menciptakan hierarki cluster. Metode ini bisa berupa agglomerative (bottom-up) atau divisive (top-down).
Agglomerative bekerja menjadikan setiap titik data sebagai cluster individu dan menggabungkannya berdasarkan kesamaan. Sementara divisive membuat semua titik data dalam satu cluster dan membaginya sampai setiap cluster hanya berisi satu titik data.
#3 Density-based clustering
Density-based clustering bekerja dengan menciptakan cluster berdasarkan kepadatan titik data. Cluster dibentuk sesuai jumlah titik dalam radius tertentu. Metode ini bisa menghasilkan cluster berbentuk arbitrer atau menyesuaikan kebutuhan analisis.
#4 Grid-based clustering
Grid-based clustering mengubah ruang data menjadi jumlah sel grid terbatas lalu melakukan operasi pada sel tersebut. Metode ini memiliki kecepatan proses yang konstan dan tidak bergantung pada jumlah objek data.
#5 Model-based clustering
Model-based clustering melibatkan pembentukan model untuk setiap cluster dan menemukan model terbaik yang cocok dengan data. Metode ini juga sering digunakan dalam statistik dan machine learning.
#6 Constraint-based clustering
Constraint-based clustering melibatkan pembentukan cluster dengan memperhatikan batasan atau kendala yang telah ditentukan sebelumnya, seperti waktu, jarak, atau batas-batas geografis.
Contoh Clustering
Statology memberikan beberapa contoh penggunaan clustering:
Pemasaran ritel
Dalam industri ritel, clustering sering dipakai untuk segmentasi pasar. Misalnya, sebuah swalayan menggunakan clustering untuk mengelompokkan pelanggan berdasarkan perilaku belanja mereka, termasuk jumlah pembelian, jenis produk yang dibeli, dan waktu belanja.
Setelah mendapatkan informasi tersebut, swalayan dapat menargetkan promosi dan penawaran khusus untuk setiap segmen pasar. Pada akhirnya, penjualan dan kepuasan pelanggan juga akan meningkat.
Kesehatan
Di bidang kesehatan, clustering bisa dimanfaatkan untuk mengidentifikasi pola dalam data pasien.
Misalnya, dokter mengelompokkan pasien berdasarkan gejala, hasil tes laboratorium, dan kondisi kesehatan lainnya. Pengelompokan ini membantu dalam diagnosis dan pengobatan yang lebih efektif.
E-mail marketing
Clustering juga berguna untuk e-mail marketing. Sebagai contoh, perusahaan menggunakan clustering untuk mengelompokkan pelanggan berdasarkan perilaku mereka saat menerima e-mail marketing yang dikirimkan oleh bisnis, seperti apakah mereka membuka e-mail, mengeklik link dalam e-mail, atau melakukan pembelian.
Dengan data tersebut, perusahaan bisa menciptakan campaign e-mail yang lebih personal dan relevan untuk setiap kelompok. Secara bertahap, strategi ini akan berdampak pada peningkatan engagement dan conversion bisnis.
FAQ (Frequently Asked Question)
Apa saja syarat clustering?
Ada beberapa syarat yang harus dipenuhi sebelum melakukan clustering, yaitu:
Fitur harus relevan dan dapat diukur
Untuk melakukan clustering, analyst memerlukan fitur atau atribut dari data yang relevan dan dapat diukur. Fitur ini bisa berupa variabel numerik atau kategorik. Jika fitur tidak dapat diukur atau tidak relevan dengan tujuan analisis, hasil clustering tidak akan informatif atau bermakna.
Ketersediaan data yang cukup
Persyaratan lain adalah ketersediaan data yang cukup. Analyst perlu memiliki jumlah data yang cukup untuk mengidentifikasi pola dan membuat cluster yang bermakna. Jika data terlalu sedikit, kemungkinan untuk mengidentifikasi cluster dengan akurat juga semakin kecil
Mengukur kemiripan atau jarak
Menentukan seberapa "mirip" atau "berbeda" objek data berguna dalam mengelompokkan data menjadi cluster. Oleh sebab itu, diperlukan metode untuk mengukur jarak atau kemiripan antara objek data.
Pemilihan metode tergantung pada jenis data dan tujuan analisisnya. Beberapa metode yang bisa dipilih yaitu jarak Euclidean, jarak Manhattan, atau koefisien korelasi Pearson.
Memilih algoritma clustering yang tepat
Tidak semua algoritma clustering cocok untuk setiap jenis data atau setiap tujuan analisis. Oleh karena itu, analyst perlu memilih algoritma clustering yang paling cocok dengan kebutuhan perusahaan.
Misalnya, jika data terdistribusi secara tidak normal, DBSCAN bisa menjadi algoritma yang tepat dibandingkan K-Means.
Memvalidasi hasil clustering
Setelah melakukan clustering, perlu dilakukan validasi hasil. Tahap ini bertujuan untuk memeriksa apakah cluster yang dihasilkan relevan dengan tujuan analisis.