Apa itu K Means Clustering?

K Means clustering adalah algoritma unsupervised machine learning yang digunakan untuk pengelompokan data dan pengenalan pola.
Caranya adalah dengan memilih beberapa titik data awal (k) secara acak, lalu memindah-mindahkannya hingga pengelompokan yang paling ideal ditemukan.
K Means clustering sering digunakan dalam berbagai bidang, seperti segmentasi gambar, segmentasi pelanggan, riset pasar, dan pengelompokan dokumen.
Proses K Means Clustering
Berdasarkan towardsdatascience.com, berikut ini adalah proses K Means clustering secara garis besar:
Pilih jumlah cluster (k) yang ingin dibuat, misalnya, k=3.
Pilih titik data k secara acak dan letakkan tiap titik ke cluster-nya sebagai centroid (pusat cluster) awal. Gambar di bawah ini menunjukkan tanda x sebagai centroid-nya.
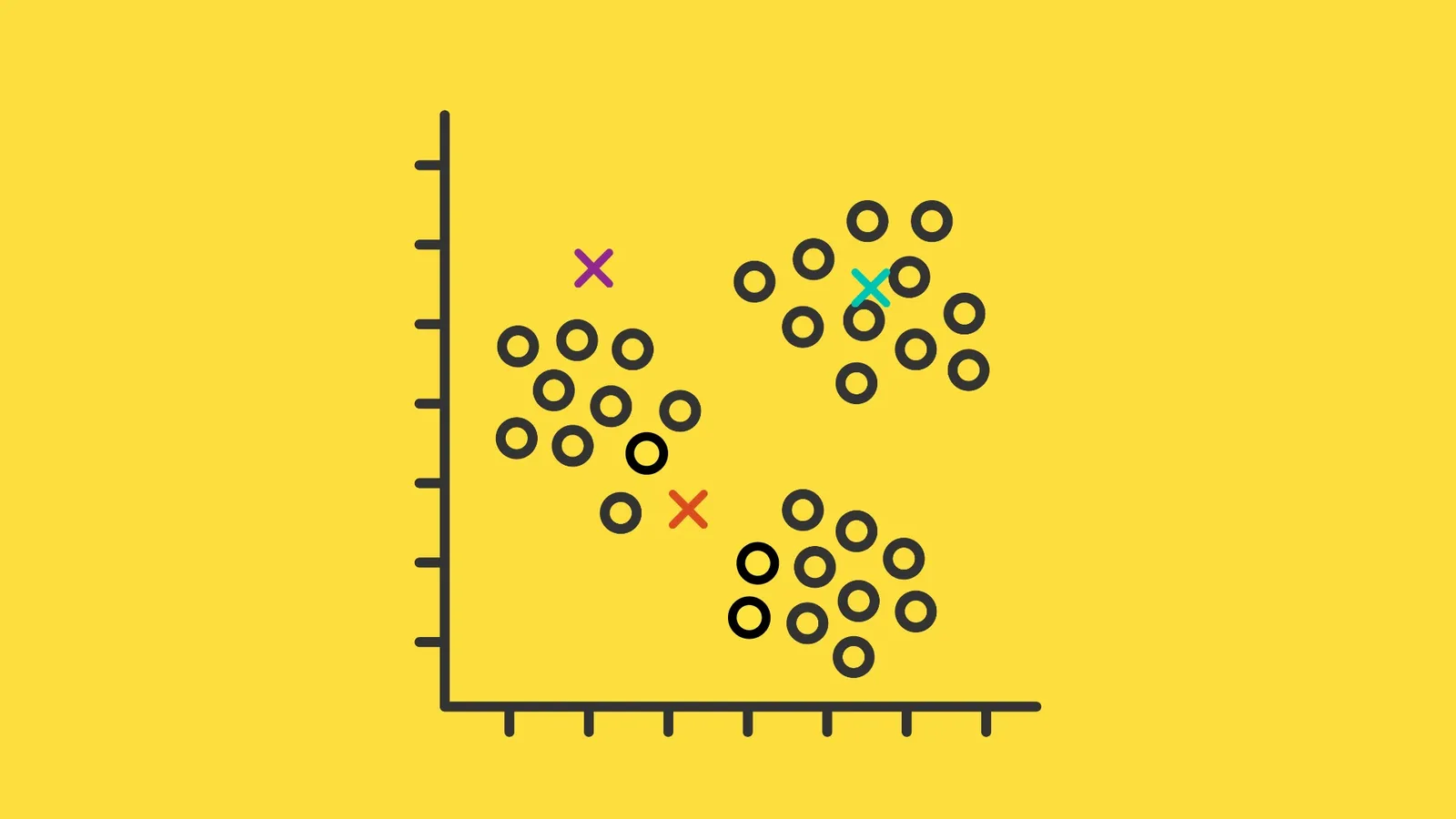
Kelompokkan semua titik data sesuai dengan jarak centroid terdekat yang telah dibuat. Langkah ini membutuhkan penghitungan jarak menggunakan Euclidean distance.
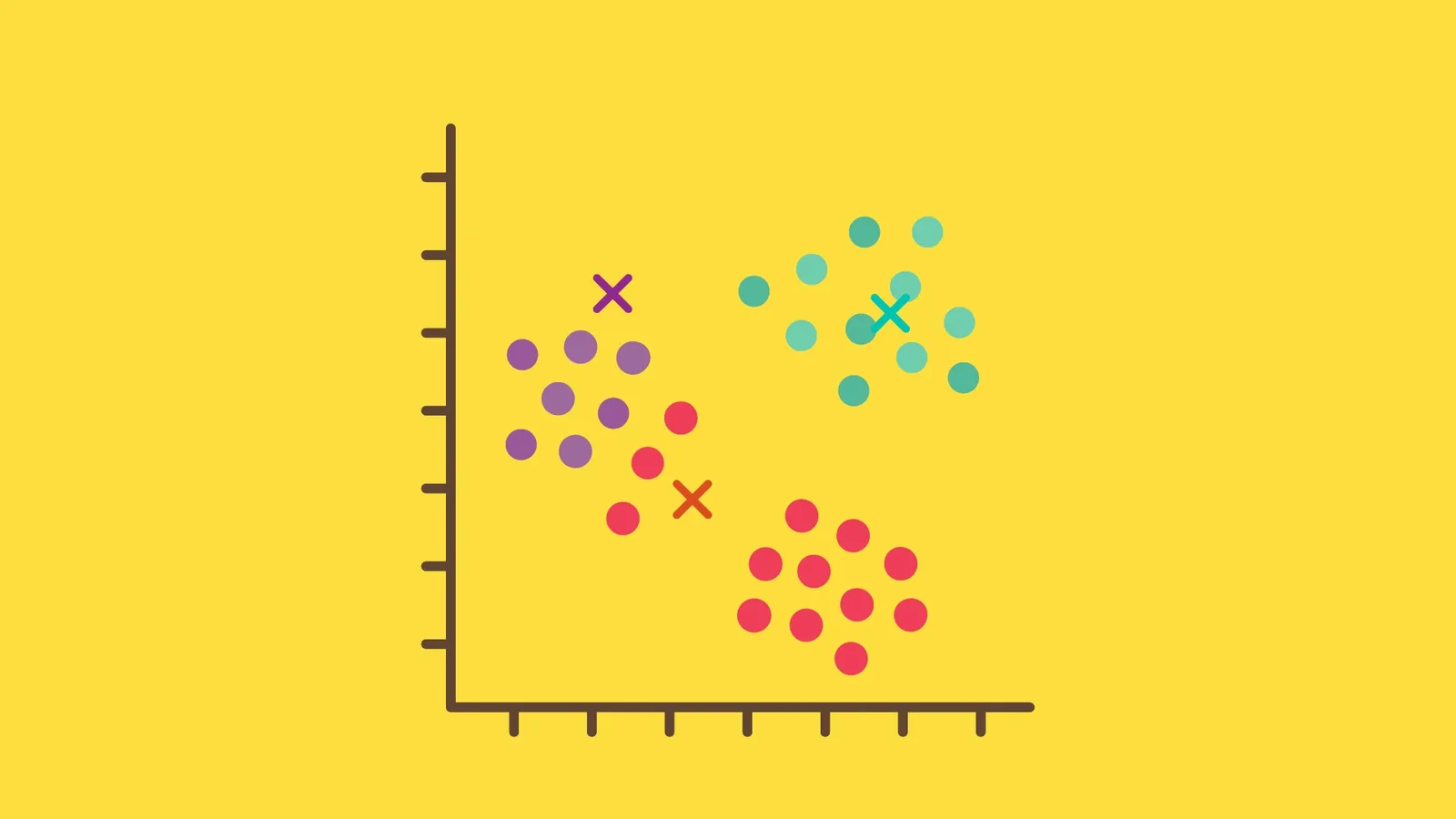
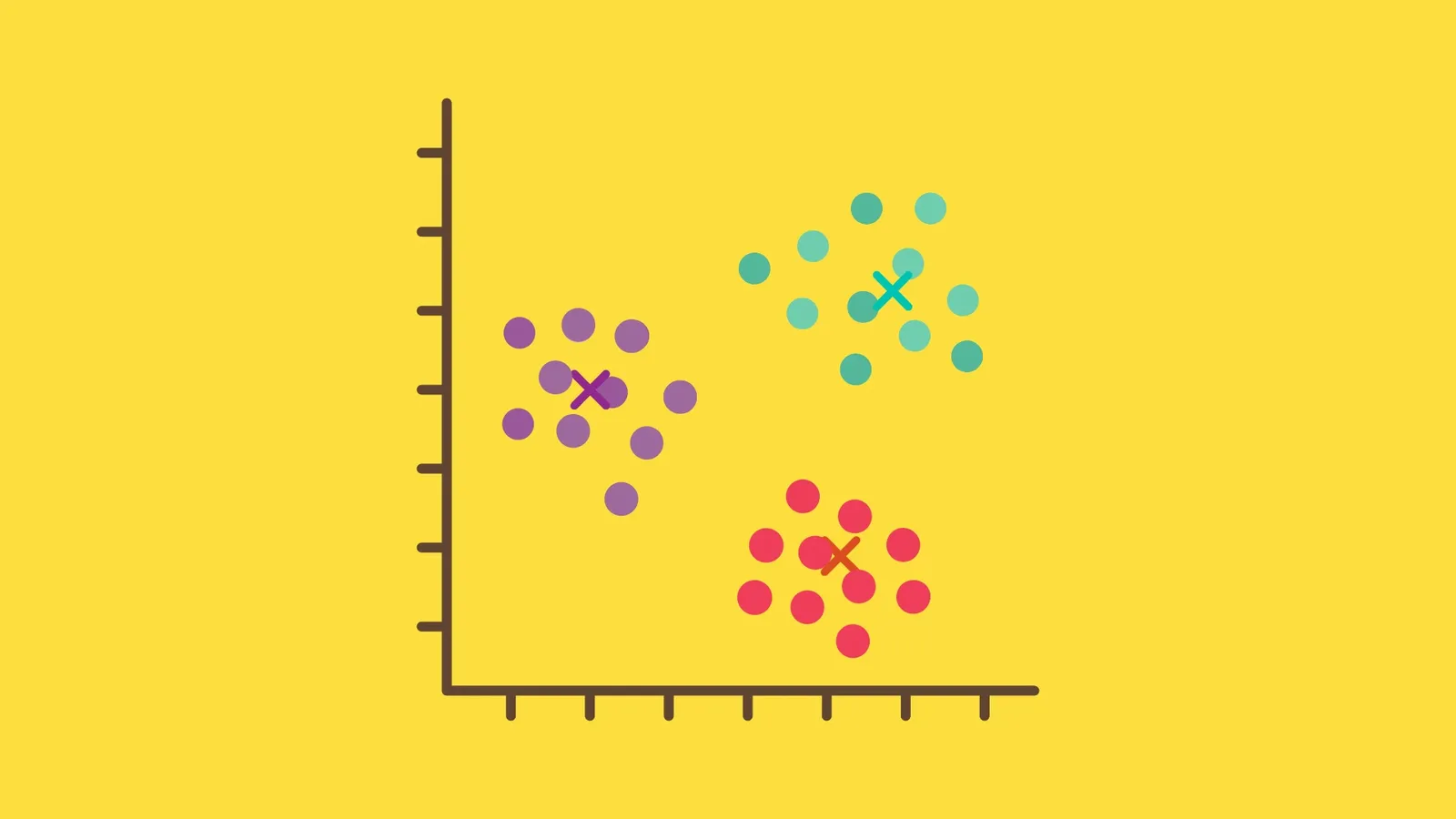
Kelebihan K Means Clustering
Berdasarkan Google, berikut ini adalah kelebihan K Means clustering:
Sederhana: dapat digunakan oleh orang-orang dengan pengetahuan pemrograman yang terbatas.
Mampu mengolah kumpulan data besar: dapat digunakan pada data dalam jumlah besar tanpa menghabiskan terlalu banyak waktu.
Konvergensi: algoritma ini pada akhirnya akan menghasilkan kumpulan cluster yang stabil.
Adaptasi dengan data baru: saat titik data baru tersedia, algoritma baru dapat dijalankan kembali untuk memasukkannya ke dalam cluster.
Generalisasi: dapat melakukan generalisasi cluster dengan berbagai bentuk dan ukuran, seperti cluster elips, sehingga dapat digunakan untuk menemukan pola dalam berbagai kumpulan data.
Kekurangan K Means Clustering
Mengutip dari Google, kekurangan K Means clustering adalah:
Memilih secara manual: jumlah cluster (k) harus dipilih secara manual, yang bisa jadi sulit dan subjektif. Memilih nilai k yang salah dapat mengakibatkan hasil pengelompokan yang buruk, dan memilih nilai k yang optimal membutuhkan pengetahuan yang cukup mengenai kumpulan data.
Bergantung pada nilai centroid awal: karena bergantung pada nilai centroid yang ada di awal, algoritma ini mungkin tidak selalu dapat menemukan clustering yang ideal, sehingga perlu menjalankan algoritmanya beberapa kali untuk menemukan solusi optimal.
Pengelompokan data dengan berbagai ukuran dan kepadatan: kelompok dalam data yang memiliki ukuran dan kepadatan berbeda dapat mengakibatkan beberapa cluster jadi tidak seimbang. Hal ini dapat mempersulit interpretasi cluster yang dihasilkan.
Pengelompokan outlier: outlier adalah titik data yang secara signifikan berbeda dari titik data lain dalam suatu kumpulan data. Outlier dapat mendistorsi hasil pengelompokan dengan menarik centroid menjauh dari pusat cluster yang sebenarnya.
Penghitungan data dengan banyak dimensi: dengan bertambahnya jumlah dimensi, pengelompokan data akan sulit karena perhitungan jarak antara titik data dan centroid menjadi lebih kompleks. Maka dari itu, diperlukan proses untuk mengurangi dimensi atau modifikasi algoritma.
Contoh K Means Clustering
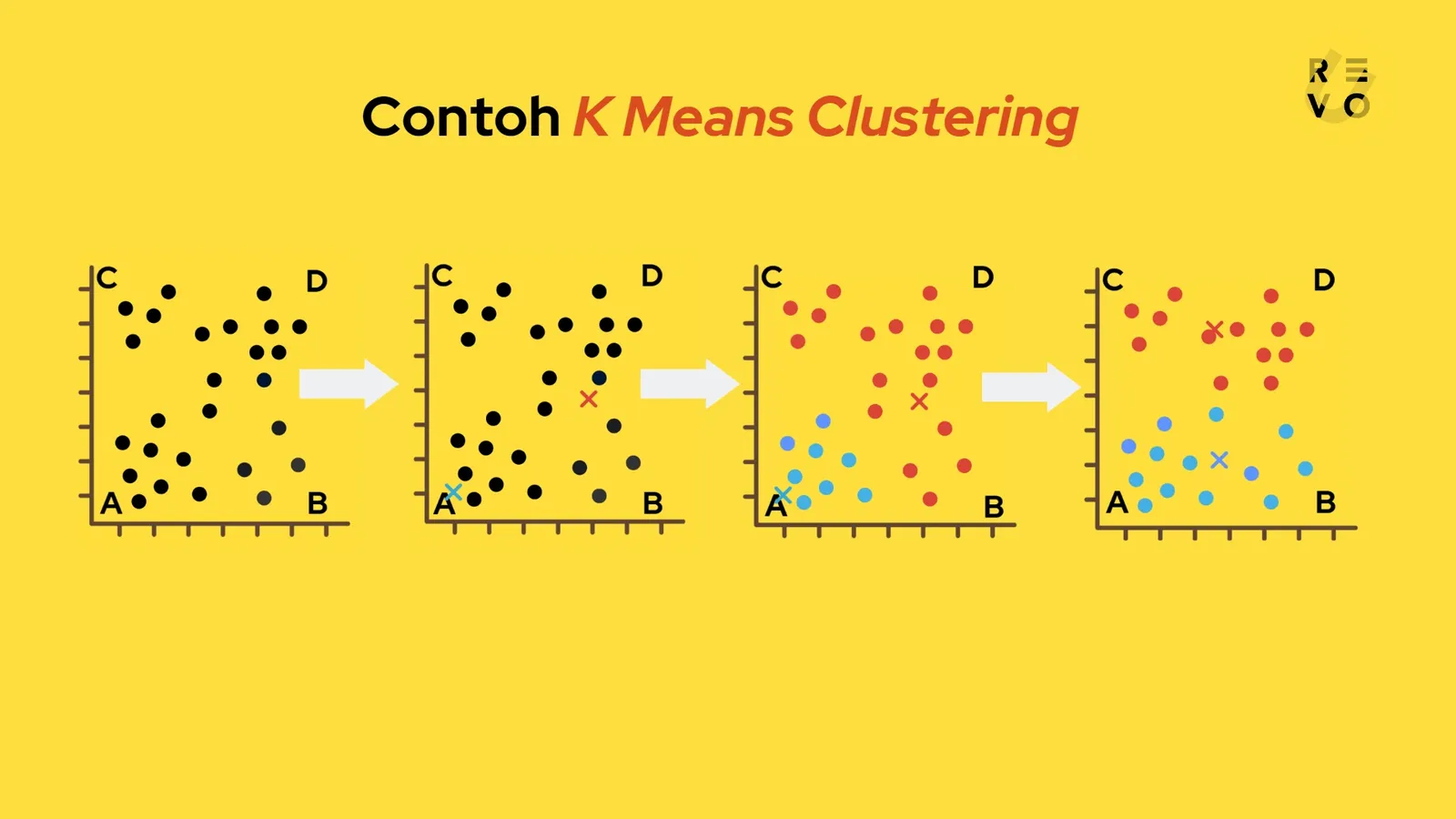
Di bawah ini adalah contoh K Means clustering sederhana. Dalam praktiknya, algoritma ini bisa lebih kompleks dan memerlukan lebih banyak iterasi atau pengulangan.
Misalnya, seorang peneliti mengumpulkan data tentang lokasi empat jenis tanaman yang berbeda di lapangan, berlabel A, B, C, dan D.
Dia kemudian ingin mengelompokkan tanaman tersebut menjadi dua kelompok berdasarkan lokasinya, sehingga dia dapat mempelajari karakteristik tanaman tersebut.
Maka, yang dia perlu lakukan adalah:
Tentukan jumlah cluster (k) nya. Dalam hal ini, k=2
Pilih titik k sebagai centroid awal secara acak. Misalnya, dia memilih titik (1, 1) dan (5, 4) sebagai centroid awal.
Kelompokkan setiap titik data sesuai dengan centroid-nya.
Ulangi langkah 3 hingga centroid yang ideal ditemukan, yaitu saat titik-titik pada cluster tidak lagi bervariasi.
FAQ (Frequently Asked Question)
Kenapa memilih K Means Clustering?
Berikut ini adalah beberapa alasan mengapa perusahaan sebaiknya memilih K Means clustering:
#1 Suatu proyek membutuhkan banyak kontributor
Jika sedang mengerjakan proyek yang melibatkan banyak kontributor, K Means clustering merupakan pilihan yang ideal karena algoritma ini cukup populer sehingga banyak orang familiar dengannya. Dengan demikian, kolaborasi proyek dapat berjalan dengan baik.
#2 SDM memiliki pengetahuan terbatas
K Means clustering juga dapat berguna jika suatu perusahaan memiliki pengetahuan terbatas mengenai machine learning yang kompleks. Algoritma ini cukup mudah dipahami dan banyak sumber untuk mempelajarinya.
#3 Kumpulan data yang besar
K Means clustering berguna untuk mengelompokkan data yang besar. Pengelompokan kumpulan data besar secara manual bisa memakan waktu dan rentan terhadap kesalahan. Dengan K Means clustering, proses grouping data dapat berjalan secara otomatis sehingga perusahaan bisa fokus pada analisis dan interpretasi hasil saja.