Apa itu Apache Spark?

Apache Spark adalah sebuah platform data processing terdistribusi open-source yang dirancang untuk pemrosesan dan analisis data skala besar dengan kecepatan tinggi.
Platform ini menonjol karena kemampuannya dalam in-memory processing, memungkinkannya melakukan operasi data dengan kecepatan jauh lebih tinggi dibandingkan dengan sistem pemrosesan batch tradisional lain.
Dengan kemampuan in-memory computing-nya, Spark mampu mengurangi jumlah pembacaan dan penulisan ke disk, yang secara signifikan meningkatkan kecepatan pemrosesan data dibandingkan dengan sistem yang bergantung pada operasi disk. Hal ini menjadikan Spark efektif untuk analisis data yang memerlukan respons cepat, seperti analisis interaktif dan machine learning.
Arsitektur Spark berpusat pada konsep Resilient Distributed Datasets (RDD), yaitu kumpulan data terdistribusi yang dapat dioperasikan secara paralel. RDD ini dirancang untuk efisiensi, toleransi kesalahan, dan kemudahan penggunaan dalam pemrosesan data terdistribusi. Spark menyediakan API yang mumpuni untuk Scala, Java, Python, dan R, sehingga memudahkan pengembangan aplikasi.
Selain itu, Spark mendukung berbagai jenis workload, termasuk batch processing, streaming data, kueri interaktif, machine learning, dan pemrosesan grafik.
Sejarah Apache Spark
Apache Spark berawal dari sebuah proyek di AMPLab, University of California, Berkeley pada tahun 2009. Tujuan utama dari proyek ini adalah untuk mengatasi keterbatasan MapReduce, sebuah model pemrograman yang digunakan untuk memproses dataset besar dengan algoritma terdistribusi dan paralel.
MapReduce (dikembangkan oleh Google) memiliki tantangan dalam proses multi-step, memerlukan banyak pembacaan dan penulisan data ke disk, sehingga memperlambat eksekusi.
Spark diciptakan untuk meningkatkan efisiensi dan memudahkan penggunaan MapReduce. Dengan melakukan pemrosesan in-memory dan mengurangi jumlah step dalam sebuah pekerjaan, Spark mampu mengeksekusi tugas lebih cepat. Spark juga menggunakan cache in-memory untuk mempercepat algoritma machine learning, memanggil fungsi yang sama berulang kali pada dataset yang sama.
Pada tahun 2013, Spark memasuki status inkubasi di Apache Software Foundation dan pada awal 2014, Spark menjadi salah satu proyek top-level di Foundation.Saat ini, Spark telah berkembang menjadi proyek aktif di bawah naungan Apache Software Foundation. Proyek ini didukung oleh komunitas yang terdiri dari kontributor individu serta dukungan korporat besar dari perusahaan-perusahaan seperti Databricks, IBM, dan Huawei dari China.
Kegunaan Apache Spark
Berdasarkan Amazon Web Services dan Databricks, berikut beberapa kegunaan utama dari Apache Spark:
Pemrosesan data real-time: Spark mampu menangani data streaming secara real-time. Artinya, Spark dapat mengolah data yang masuk secara langsung dan kontinu, seperti data dari sensor atau transaksi keuangan.
Analitik interaktif dan query: Spark mendukung query interaktif yang membantu analyst untuk menjalankan analisis dan mendapatkan hasil secara cepat. Hal ini berguna untuk analisis bisnis dan pengambilan keputusan berbasis data.
Machine learning: dengan dukungan untuk machine learning, Spark memungkinkan pengembangan model yang dapat belajar dari data besar, berguna dalam berbagai aplikasi seperti rekomendasi produk, deteksi penipuan, dan lainnya.
Pemrosesan grafik: Spark juga mendukung pemrosesan grafik. Analyst dapat menganalisis dan memanipulasi data yang terstruktur sebagai grafik, seperti social network atau jaringan komunikasi.
Dukungan bahasa pemrograman: Spark mendukung berbagai bahasa pemrograman termasuk Java, Scala, Python, dan R, membuatnya mudah diintegrasikan ke dalam berbagai aplikasi dan sistem.
Analitik lanjutan: Spark mendukung SQL queries. Analyst dapat melakukan query dan analisis data dengan cara yang lebih familiar bagi mereka yang sudah terbiasa dengan SQL.
Contoh Penggunaan Apache Spark
Berikut beberapa contoh penggunaan Apache Spark dalam berbagai skenario:
Analisis sentimen media sosial: Spark bisa dipakai untuk mengolah dan menganalisis data media sosial secara real-time untuk menentukan sentimen umum terhadap suatu topik atau brand. Misalnya, perusahaan menggunakan Spark untuk menganalisis tweet tentang produk mereka agar memahami persepsi pelanggan.
Rekomendasi produk e-commerce: dengan menggunakan algoritma machine learning yang tersedia di MLlib, Spark dapat dimanfaatkan untuk mengembangkan sistem rekomendasi yang mempersonalisasi pengalaman belanja pelanggan berdasarkan perilaku pembelian dan preferensi masing-masing.
Pemrosesan log data: Spark cocok untuk menganalisis log data dari web server atau aplikasi untuk memantau pola traffic, aktivitas user, atau mendeteksi kegiatan mencurigakan seperti cyber attack.
Analisis data keuangan: Spark juga berguna untuk analisis data keuangan skala besar, seperti deteksi penipuan dalam transaksi kartu kredit atau analisis pasar saham real-time.
Pengolahan data IoT: dalam konteks Internet of Things (IoT), Spark dapat digunakan untuk mengolah data yang dihasilkan oleh perangkat IoT, seperti sensor, untuk melakukan pemantauan kondisi real-time atau analisis prediktif.
FAQ (Frequently Asked Question)
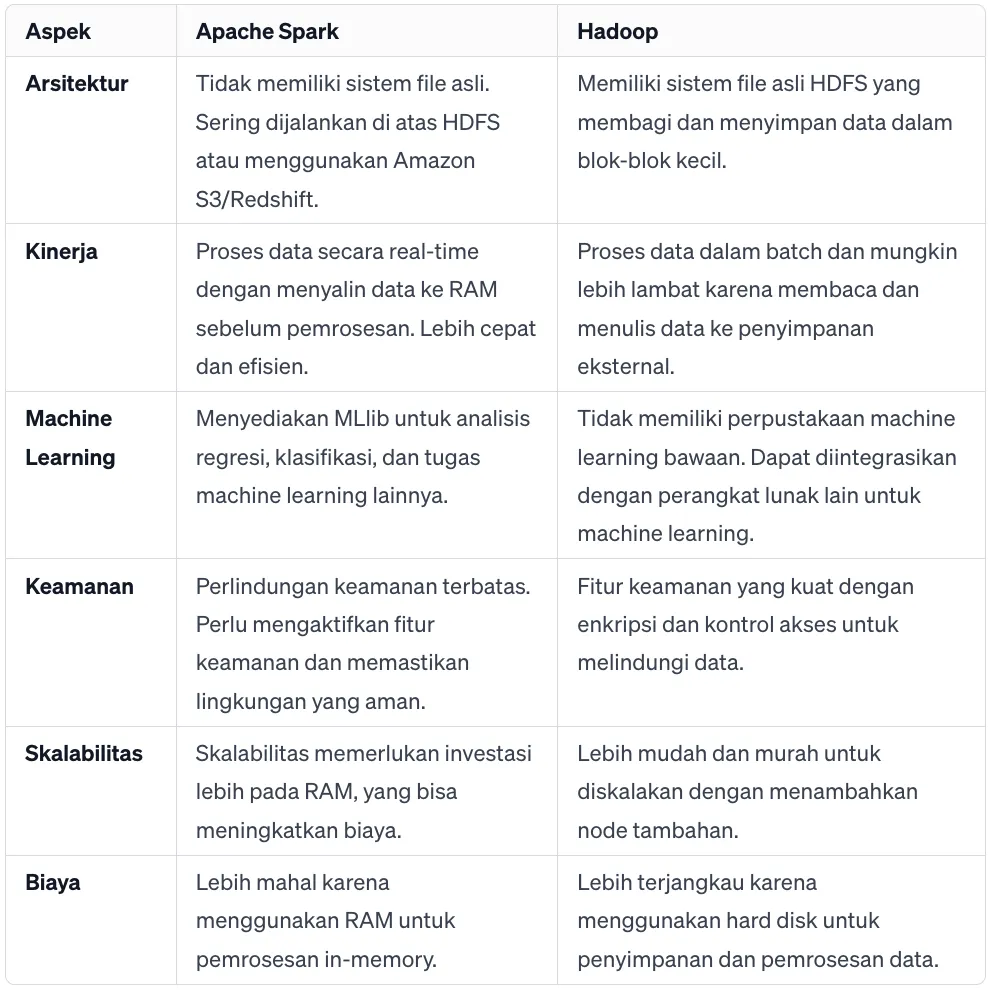
Apa perbedaan Apache Spark vs Hadoop?
Apache Spark adalah sistem pemrosesan data terdistribusi open-source yang dirancang untuk pemrosesan data skala besar dan analitik cepat. Spark menyediakan kemampuan in-memory processing, memungkinkannya melakukan operasi data dengan kecepatan tinggi dibandingkan dengan sistem batch processing tradisional.
Di sisi lain, Hadoop adalah framework open-source untuk penyimpanan dan data processing skala besar. Hadoop lebih berfokus pada batch processing data yang efisien dan dapat menangani berbagai jenis data, dari terstruktur sampai tidak terstruktur.
Secara singkat, perbedaan utama antara keduanya terletak pada cara masing-masing memproses data. Spark dioptimalkan untuk pemrosesan in-memory dan analitik cepat, sedangkan Hadoop berfokus pada batch processing data yang efisien dan penyimpanan data terdistribusi.
Lebih detail, berikut tabel perbedaan Apache Spark vs Hadoop: