Apa itu Crawler?
Kombinasi internet dengan search engine memungkinkan semua orang bisa mendapatkan informasi yang diinginkan dengan mudah dan cepat. Namun agar informasi ini bisa sampai ke pembaca, ada serangkaian proses yang perlu dilakukan.
Ketika suatu informasi diunggah ke internet, misalnya postingan blog atau e-commerce, mesin pencari akan melakukan crawling terlebih dahulu.
Crawling merupakan proses yang dilakukan oleh search engine untuk menelusuri atau merayapi seluruh informasi yang ada di internet sesuai dengan kueri yang diberikan. Proses ini dilakukan dengan bantuan bot yang disebut dengan web crawler atau crawler.
Crawler adalah bot search engine yang digunakan khusus untuk menemukan, mengunjungi, dan menganalisis konten website dan informasi lainnya yang ada di internet.
Setelah merayapi website, web crawler akan melakukan indexing atau menggabungkan halaman web tersebut dengan halaman web lain yang membahas informasi sejenis.
Ketika ada pengguna yang mencari informasi tersebut, search engine akan dengan cepat menampilkan informasi yang diminta dari database halaman web yang telah diindeks.
Fungsi Crawler
Crawler berfungsi untuk mempelajari berbagai halaman web, informasi yang dimuat di web tersebut sehingga web bisa diindeks. Sehingga ketika pengguna mencari suatu informasi, search engine bisa memberikan website yang relevan dengan permintaan yang dikirimkan.
Web crawler secara sistematis melakukan penelusuran halaman web secara rutin. Ketika ada perubahan pada suatu web, crawler akan melakukan perayapan dan indexing kembali.
Misalnya, awalnya blog A membahas tentang skincare untuk wanita paruh baya. Maka ketika pengguna mencari informasi mengenai skincare untuk wanita paruh baya, blog A akan ditampilkan oleh search engine.
Namun konten terbaru blog tersebut lebih banyak membahas tentang resep masakan, web crawler akan mengidentifikasi blog sebagai website khusus makanan.
Faktor-faktor yang Dipertimbangkan Crawler
SEO sangat memengaruhi kerja crawler. Website yang mengikuti prinsip SEO dapat memudahkan crawler menemukan website.
Ketika website eror, crawler sulit bahkan tidak bisa menemukan web. Akhirnya, peringkat website di halaman pencarian (SERP) akan menurun dan menyebabkan website sulit ditemukan pengguna.
Berikut ini beberapa faktor atau aturan crawler dalam merayapi website:
Jumlah halaman yang tertaut
Crawler memiliki prioritas halaman web yang perlu dirayapi terlebih dahulu, salah satunya berdasarkan jumlah halaman lain yang ditautkan ke halaman tersebut (backlink).
Semakin sering suatu halaman dikutip oleh website lain dan mendapatkan banyak pengunjung, menandakan halaman tersebut berisi informasi yang relatif berkualitas. Jadi penting bagi crawler untuk merayapi dan mengindeksnya.
Konten sering di-update
Konten web yang sering diperbarui, dihapus, atau dipindahkan ke lokasi baru akan dikunjungi secara berkala oleh web crawler. Hal ini untuk memastikan versi konten terbaru diindeks dan bisa ditampilkan ke pengunjung.
Persyaratan robot.txt
Sebelum merayapi web, crawler akan memeriksa file robot.txt yang di-hosting oleh server web laman tersebut.
File robot.txt berisi seperangkat aturan untuk setiap bot yang mengakses web atau aplikasi yang dihosting. Aturan ini menentukan halaman mana yang bisa dirayapi, dan tautan URL mana yang bisa diikuti.
Contoh Kerja Crawler
Andita merupakan seorang blogger yang sudah lama aktif menulis blog. Blog-nya berfokus pada review skincare dan kosmetik, dan ia cukup aktif menulis di blog-nya.
Ketika Andita meng-upload konten yang membahas rekomendasi parfum wanita terbaik 2023, web crawler secara otomatis merayapi website tersebut. Setelah dilakukan penelusuran, bot akan mengindeksnya agar bisa ditampilkan ke pengguna dengan mudah.
Jadi ketika ada pengguna mencari “Rekomendasi parfum wanita terbaik 2023”, search engine akan menampilkan website Andita bersama dengan web lain yang membahas informasi sejenis.
FAQ (Frequently Asked Question)
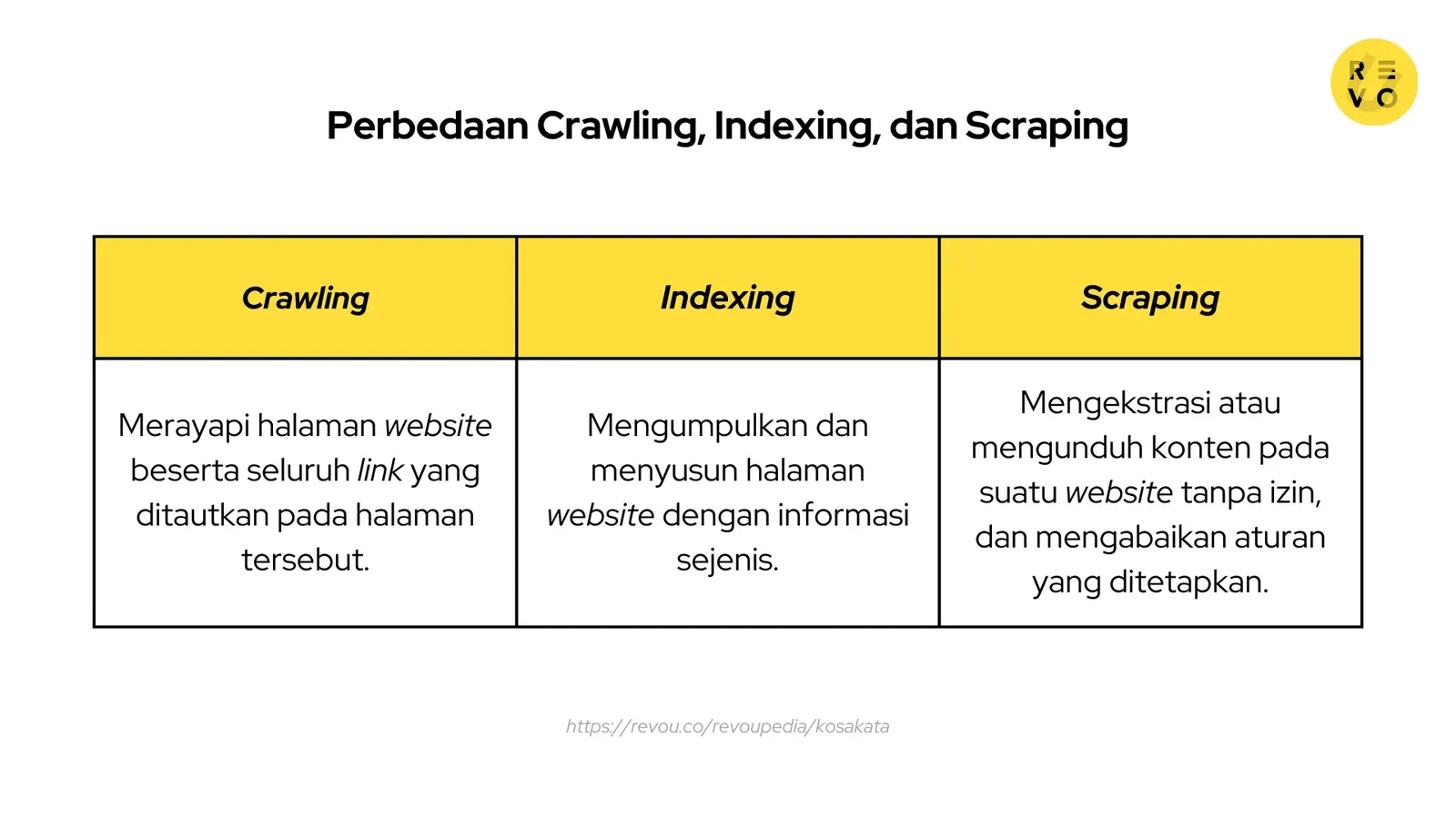
Apa perbedaan crawling dan indexing?
Crawling dan indexing adalah proses yang dilakukan bot search engine dalam mengumpulkan informasi di internet, dan menampilkannya ke pengguna sesuai kata kunci yang dimasukkan.
Crawling adalah proses ketika bot melakukan perayapan atau penelusuran ke halaman website. Selanjutnya, bot akan melakukan indexing.
Indexing adalah menggabungkan dan menyimpan halaman website dengan halaman web lain yang membahas informasi sejenis. Halaman-halaman tersebut kemudian disusun dalam bentuk daftar, seperti daftar isi pada buku.
Ketika pengguna mencari informasi tersebut, search engine akan menampilkan daftar link website yang membahas informasi relevan.
Apa perbedaan web crawling dan web scraping?
Web scraping memiliki konsep yang mirip dengan web crawling, namun keduanya sangat berbeda.
Web scraping adalah mengekstrasi atau mengunduh konten di web tertentu tanpa izin. Biasanya praktik ini hanya menargetkan satu situs saja. Sedangkan web crawling akan merayapi suatu situs beserta tautan link halaman secara terus menerus.
Selain itu web scraping tidak memiliki aturan, sedangkan web crawling melakukan perayapan berdasarkan aturan tertentu agar tidak membebani server web.
Web scraping mungkin digunakan dengan tujuan analisis untuk membuat kumpulan data yang lebih bertarget. Salah satu contohnya yaitu membantu membandingkan harga produk di beberapa penjual.
Web scraping akan mengunduh data produk dan harga dari setiap penjual setiap hari. Informasi itu sangat berguna khususnya bagi reseller atau pengecer kecil untuk mendapatkan produsen potensial sekaligus keuntungan yang besar.
Namun sering kali web scraping digunakan untuk tujuan jahat dengan mengorek data pribadi atau kekayaan intelektual.
Misalnya, perusahaan B melakukan web scraping ke perusahaan A. Tujuannya untuk memperoleh seluruh akses informasi perusahaan A, baik yang bersifat publik maupun rahasia seperti informasi produk, dan pembaruan real time harga dan promosi.